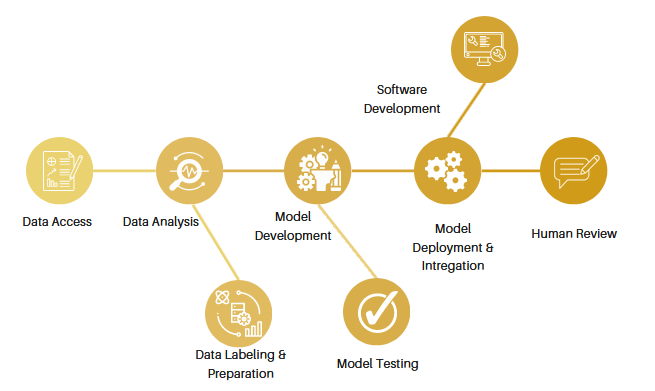
ML for Analyzing Egg Hatching

Team
- E/18/030, Aththanayake A.M.S., email
- E/18/282, Ranasinghe R.A.N.S., email
- E/18/283, Ranasinghe R.D.J.M., email
Table of Contents
Introduction
Egg hatching is a vast biological process that depends on various factors. The successful incubation of eggs plays a crucial role in the poultry industry. However, accurately determining the hatchability of eggs before they enter the incubation process remains a challenge for farmers. Currently, eggs are categorized based on their external appearance, but this method does not provide a definitive indication of whether an egg will hatch or not. As a result, farmers often face the risk of wasting valuable resources, such as incubation space and electricity, on eggs that will not successfully hatch.

Problem and Solution
The inability to predict the hatchability of eggs before incubation leads to inefficiencies and economic losses for breeder farms. Eggs that are unlikely to hatch still occupy space within the incubators and consume electricity throughout the 21-day incubation period. Additionally, the uncertainty surrounding hatchability makes it difficult for farms to accurately supply the required daily demand. Therefore, there is a need for a reliable method to determine the likelihood of hatchability for eggs before they are placed in the incubators.
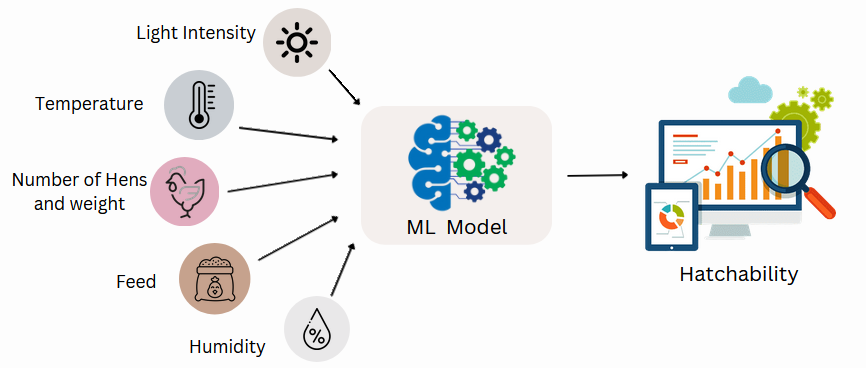
Implementing a machine learning (ML) model to predict egg hatchability offers significant benefits for breeder farms. By analyzing various factors and patterns related to egg characteristics and breeding conditions, the ML model can accurately determine the likelihood of an egg successfully hatching. This enables farmers to avoid wasting resources on eggs with low hatchability potential, optimizing incubation space and reducing electricity consumption.
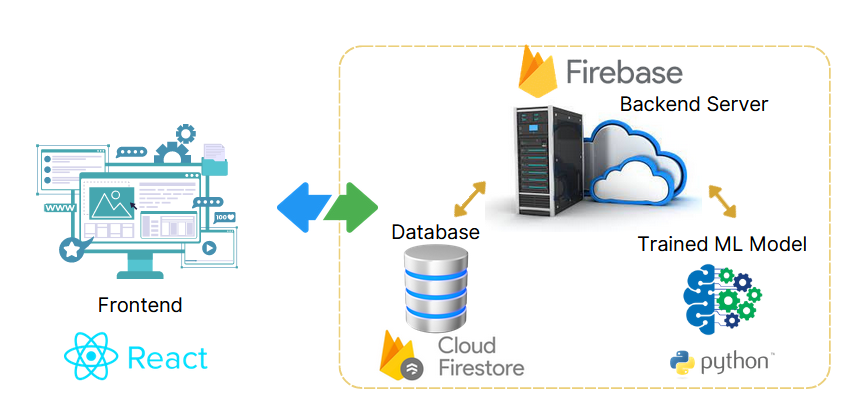
Technology Stack
Machine Learning Model
In our project, we employed a Decision Tree model with the Gini index criterion. This section outlines the key steps and insights from our machine learning approach.
Modeling approch
We chose the Decision Tree algorithm due to its interpretability and versatility. The Gini index was used as the splitting criterion, allowing the model to make decisions based on information gain and class impurity reduction.To control the complexity of our Decision Tree, we set a maximum depth of 12 nodes. This choice was based on an iterative process that involved fine-tuning various hyperparameters.
Pruning
Pruning is crucial for preventing overfitting. We carefully pruned our Decision Tree to find the optimal balance between complexity and performance.
Cross validation
To ensure our model’s robustness and generalization performance, we utilized cross-validation. This technique involves splitting the data into multiple subsets, training the model on different combinations, and evaluating its performance across various folds.
Work Plan