e19-4yp-Developing-a-Small-Scale-Financial-Language-Model
Developing a Small-Scale Financial Language Model
Team
- e19131, Kasuni Hansachapa, email
Supervisors
Table of content
- Abstract
- Related works
- Methodology
- Experiment Setup and Implementation
- Results and Analysis
- Conclusion
- Publications
- Links
Abstract
This study develops a Small Language Model (SLM) to process financial data at LEARN, enhancing decision-making with efficiency and accuracy. Trained on five years of financial statements,audit reports and spreadsheets, the model leverages quantization, pruning, knowledge distillation, and retrieval-augmented generation (RAG). QLoRA optimizes performance, while hallucination reduction ensures reliability. The system, hosted on LEARN’s servers for security, processes structured and unstructured financial data to provide accurate insights. This research highlights SLMs as a secure, regulatory-compliant alternative to LLMs for financial analysis.
Related works
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) with their ability to generate human-like text, enabling applications in code writing, math problem-solving, dialogue, and reasoning. In finance, models like BloombergGPT support automated decision-making, risk assessment, fraud prevention, and forecasting. However, their high computational cost and risk of generating incorrect outputs pose challenges.
Small Language Models (SLMs) offer a resource-efficient alternative with domain-specific accuracy. Techniques like quantization, pruning, and knowledge distillation allow SLMs to match LLM performance with lower computational demands. Fine-tuned on financial documents using QLoRA and enhanced with RAG for hallucination control, SLMs ensure high precision—critical for financial applications. As AI adoption in finance grows, regulatory frameworks and ethical standards continue to evolve.
| Feature | SLM | LLM |
|---|---|---|
| Size & Complexity | Smaller in size, with fewer parameters | Massive in size, billions of parameters |
| Computational Requirements | Low computational power; optimized for efficiency | Requires high-end GPUs/TPUs and large-scale infrastructure |
| Training Cost | Lower cost due to smaller datasets and fewer resources | Extremely expensive due to vast datasets and high training complexity |
| Performance in General Tasks | Specialized performance, optimized for specific domains | Strong general-purpose capabilities, excelling in diverse NLP tasks |
| Accuracy & Precision | High accuracy within a specific domain (e.g., finance) | High accuracy in general NLP but prone to hallucinations in specialized fields |
| Data Efficiency | Requires fewer data for training and fine-tuning | Needs massive datasets for training and generalization |
Approaches and Techniques in Previous Research
The first part of the review covers preliminary knowledge in several approaches and techniques in previous research:
- Optimization Techniques: Methods such as quantization, pruning, imitation learning, progressive learning, knowledge distillation, and reasoning distillation are explored as strategies to enhance the efficiency of SLMs. These techniques allow smaller models to achieve comparable performance to LLMs while significantly reducing computational demands.
- Hallucination Mitigation: One of the primary concerns in financial AI applications is the generation of hallucinated or incorrect data. The paper discusses mitigation strategies, including Retrieval-Augmented Generation (RAG) and explanation tuning, which help improve the factual accuracy of model outputs. Additionally, hybrid approaches combining fine-tuned question models and RAG are examined.
- Evaluation Metrics: The review details various evaluation metrics applicable to SLMs, including perplexity, BLEU, TER, ROUGE, hallucination score, and domain-specific financial metrics like Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). These metrics are essential for assessing model performance in text generation, prediction, and information retrieval tasks. Additionally, financial benchmarks for accurate evaluation are discussed.
- Challenges in Financial SLMs: The review highlights critical challenges, such as data security, hallucination, and ethical concerns in deploying SLMs in financial applications. Financial data security is particularly emphasized, with discussions on private hosting solutions, federated learning, and differential privacy as potential safeguards.
- Domain-Specific Applications: The paper explores how SLMs are tailored for industry-specific applications, including medical, legal, retail, and financial domains. In finance, SLMs support market prediction, financial report analysis, and automated customer interactions. The importance of domain-specific fine-tuning to enhance model accuracy is underscored.
Advancements in Financial Language Models: Performance, Applications, and Trade-offs
Recent advancements in language models (LMs) have significantly improved financial tasks such as sentiment analysis, financial forecasting, and risk management. Specialized models like FINBERT (2022), BloombergGPT, and FinGPT cater specifically to financial NLP challenges, handling complex terminology and numerical data.
Key Models & Capabilities:
- BloombergGPT (50B parameters):A large-scale proprietary model for financial analysis.
- FinGPT (7B & 13B):Open-source, excelling in financial document summarization and question answering.
- FINBERT (110M):Optimized for sentiment analysis and financial entity recognition.
- InvestLM (65B):Trained on CFA exam questions and SEC filings for financial classification.
While larger models like BloombergGPT offer superior accuracy, smaller models (e.g., Google-Gemma-2B, OpenELM-270M) are more resource-efficient but struggle with complex tasks.
Model parameters count and capabilities of language models
| Finance-Specific Language Models | Model Parameters | Model Capabilities |
|---|---|---|
| BloombergGPT 50B Dataset: FinPile |
50B |
|
| FinBERT (open) Dataset: Financial PhraseBank |
110M |
|
| FLANG (open) | 110M |
|
| InvestLM (fine-tuned LLaMA-open) Dataset: CFA, SEC |
65B |
|
| FinMA (fine-tuned LLaMA-open) Dataset: PIxIU |
7B and 13B |
|
| FinGPT (open) Dataset: FinQA, FinRed |
7B and 13B |
|
| Google-gemma 2B | 2B |
|
| TinyLlama (fine-tuned LLaMA) | 1.1B |
|
| Apple-OpenELM Dataset: RefinedWeb, Pile |
270M - 3B |
|
| Microsoft-phi | 1B - 3B |
|
Methodology
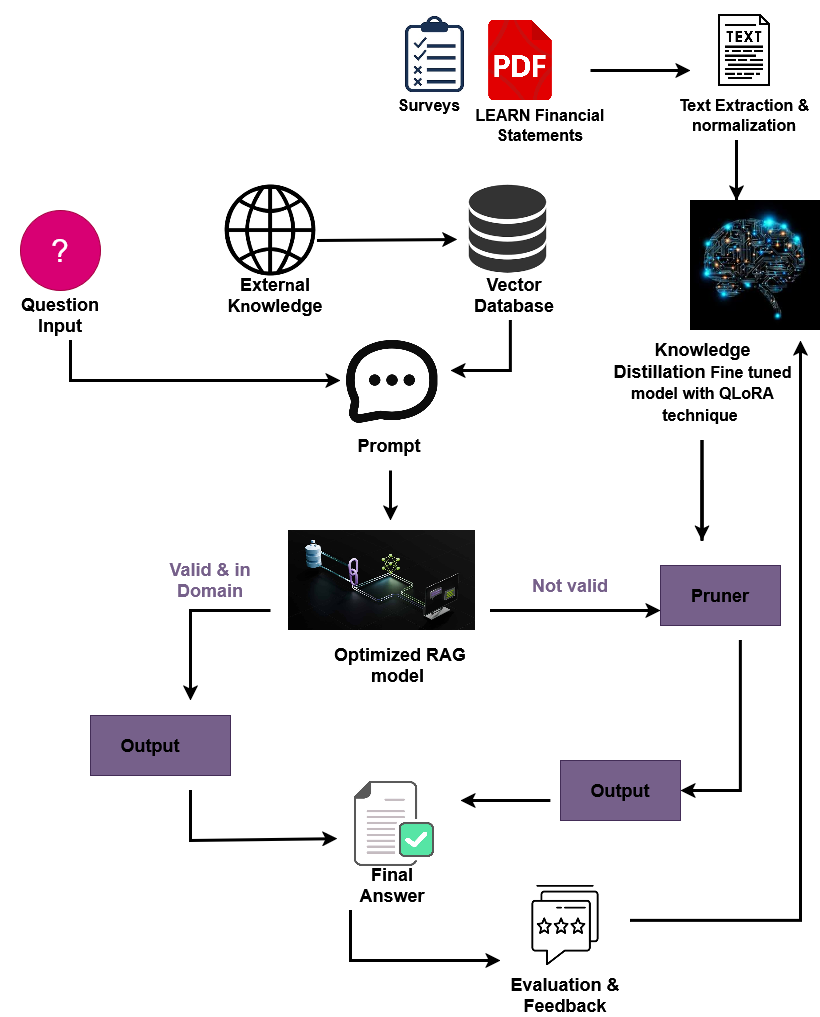
Experiment Setup and Implementation
This experimental setup was designed to evaluate the effectiveness of a small-scale financial language model using FinGPT enhanced with Retrieval-Augmented Generation (RAG) and fine-tuned via QLoRA (Quantized Low-Rank Adaptation). The system was deployed on a local server with the following specifications:
- Operating Systemr: Ubuntu 24.04.2 LTS (Noble Numbat)
- Processor: Intel(R) Core(TM) i7-8700B CPU @ 3.20GHz
- CPU Cores: 8 cores (1 thread per core)
- Memory (RAM): 24 GB
- Disk Space: 28.37 GB (32.7% used)
- Architecture: x86_64 (64-bit)
- Virtualization: Running under KVM (full virtualization)
- GPU: Not available (4-bit quantization used for CPU inference)
1. Data Acquisition and Preprocessing
Financial statement PDFs (e.g., balance sheets, income statements, cash flow statements) were collected from publicly available sources. We used PyMuPDF to extract and clean text, chunking the data into semantically meaningful units.
2. Vector Embedding and Retrieval Index
Text chunks were embedded using all-MiniLM-L6-v2 from SentenceTransformers. Embeddings were indexed using FAISS for fast retrieval in the RAG pipeline.
3. Fine-Tuning with QLoRA
The base model yentinglin/FinGPT-4B was fine-tuned using QLoRA with curated financial QA datasets. Training occurred in 4-bit precision using CPU, enabling low-resource adaptability.
4. RAG Pipeline Integration
A custom RAG pipeline was implemented:
- Relevant documents retrieved from FAISS index
- Prompt constructed using the retrieved content
- Response generated by the fine-tuned FinGPT model
This architecture enables domain-grounded answers and minimizes hallucination in financial NLP tasks.