
An Artificial Intelligence Inspired Zero Trust Model in Decentralized Edge Environment
Team
- E/16/242, Munasinghe A.V.S.S.A, e16242@eng.pdn.ac.lk
- E/16/286, Piyarathna M.G.N.H, e16286@eng.pdn.ac.lk
- E/16/399, Wijerathna D.G.K.E, e16399@eng.pdn.ac.lk
Supervisors
- Dr. Upul Jayasinghe, upuljm@eng.pdn.ac.lk
- Dr. Suneth Namal Karunaratne, namal@eng.pdn.ac.lk
Table of content
- Abstract
- Related works
- Methodology
- Experiment Setup and Implementation
- Results and Analysis
- Conclusion
- Publications
- Links
Abstract
Zero trust is a security concept in which no entity or user is automatically trusted—instead, all access must be individually validated through a rigorous set of checks and controls. This approach is based on the idea that no environment can be fully trusted and that protection must be applied holistically across networks, applications, and workloads. Machine learning can be used to implement Zero Trust by enabling the application of dynamic, risk-based access policies based on real-time user behaviour. Machine learning algorithms can analyze characteristics such as device identity, authentication methods, and resource access patterns to identify anomalies and provide adaptive authentication methods for users. Additionally, machine learning can be used for continuous monitoring of user behaviour and malicious activity, allowing organizations to detect and prevent security threats. In this research, we have implemented a zero-trust model which follows the basic principles of zero trust such as Guaranteeing secure access to all resources, No implicit trust based on location, and Continuous verification using machine learning.
Related works
The word “Zero Trust” was introduced by John Kindervag from Forrester Research and it is based on the principle of “Never trust Always Verify”.Forrester uses a centralized segmentation gateway with multiple zones and each zone includes a “microcore and perimeter” (MCAP ) interface. Forrester’s Next Generation Firewall (NGFW) is used as a segmentation engine and connected to multiple MCAPS. The segmentation engine receives the traffic from MCAP segments and forwards them into Data Acquisition Network (DAN) MCAPs in order to analyze them to make decisions about the clients.
Google BeyondCorp is a security framework that emphasizes a zero-trust approach to network security. Zero trust is a security model that assumes no user, device, or application can be trusted by default, even if they are inside the network perimeter. Instead, access to resources is based on identity, context, and policy, regardless of the user’s location or the device they’re using. BeyondCorp implements this model by using contextual information such as user identity, device security posture, and network location to enforce access controls and authorization decisions. This approach reduces the risk of data breaches and improves security posture for organizations, and it’s used by Google to protect its own internal networks and employees can use network resources from any location without the need for a traditional VPN.
An Artificial Intelligence Approach for Deploying Zero Trust Architecture (ZTA)
The paper highlights the growing importance of Zero Trust Architecture (ZTA) as a cybersecurity framework for protecting organizational networks against advanced threats because the traditional approach of implementing ZTA can be challenging, time-consuming, and resource-intensive. The paper proposed a NIST-based policy engine which consists of static policies(a well-known fact by now), security feeds(To maintain the same security posture as older security controls) and ML policies. The final algorithm works as follows. First, it tries to make a decision based on static policies. If a decision cannot be made, security feeds are used to make the decision. If it fails to make a decision, the ML model is used to derive the decision.
Methodology
Before doing anything data preprocessing was applied to the raw dataset and the following techniques were applied.
- Data cleaning (Null, Missing, hex values)
- If some column contains high Null values or missing values percentage, the corresponding column was dropped
- Some columns contain values in hex format. Since model training is not possible with hex values, those values are converted to integer values
- Creating attack-wise labels
- Original dataset has a label called attack_type. But our task, it was required nine different labels for nine attack types.
| attack_type |
|---|
| Dos |
| Analysis |
Before
| attack_type | Dos | Analysis |
|---|---|---|
| Dos | 1 | 0 |
| Analysis | 0 | 1 |
After
- Encode the categorical data to numerical format
- Splitting the data (60%,20%,20%) for train, test and online learning
- 60%: training machine learning models
- 20%: testing the models
- 20%: online learning for better tuning of the models
Original dataset comes with 49 traffic features and around 2.5 million records. To reduce the computational complexity of model training, feature selection techniques were applied to select the most appropriate features. Following is the roadmap for the feature selection,
- Remove features with High correlation
- Used Information gain to reduce features
- Used variable threshold method to identify constant features
- Chi-Square statistical Analysis
When considering the methodology, dataset with selected features were fed into nine machine learning models. For one training model,
- Only one attack label was fed. For Dos attacks,
| attack_type | Dos |
|---|---|
| Dos | 1 |
| Analysis | 0 |
- To select the best algorithm for one machine learning model, a few algorithms were tried.
- Logistic Regression
- Decision Tree Regressor
- Random Forest Regressor
- K Nearest Neighbors Regressor
- Deep Neural Network
- SVM Regressor
- Isolation Forest
- One Class SVM
As the output of machine learning models probability values were taken out. Hence, for one traffic data, there will be nine different probability values corresponding to nine different attacks. Then for each machine learning model’s output, a suitable threshold value was defined based on accuracy and F1 score. In this way, we can get a direct idea about the attack type for a particular traffic data. As an example,
- Threshold for DoS attacks: 90%
If we get a higher probability value than 0.9 when traffic data is fed into the model related to the DoS attacks, we can conclude that traffic data has a high probability to be a DoS attack.After that, it was required to combine nine probability values and derive one trust value. Here, ensemble learning techniques were used to derive the final trust value. Candidates used for this project are listed below,
- Logistic Regression
- Passive-aggressive Classifier
- Approximate Large Margin Algorithm Classifier(ALMA)
At this point, we have the final trust value. Defining the boundary between trustworthiness and untrustworthiness can be done by considering the accuracy and F1 score. Furthermore, for better fine-tuning of the models, online learning was done using Logistic Regression, Passive-aggressive Classifier and Approximate Large Margin Algorithm Classifier(ALMA). The whole process is shown in figure 1.
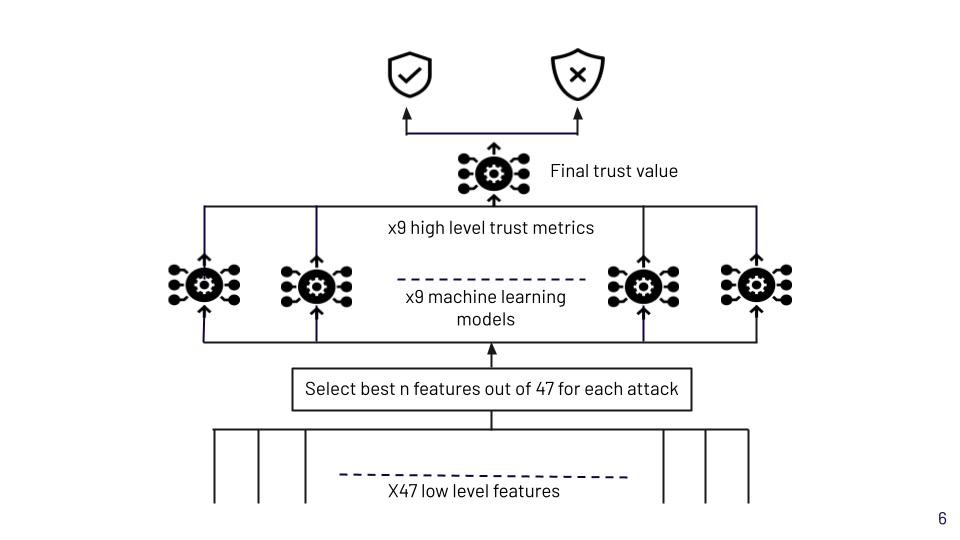
Figure 1
Experiment Setup and Implementation
This project used the UNSW NB15 dataset for training our Machine Learning models which are publicly available on https://research.unsw.edu.au/projects/unsw-nb15-dataset . This dataset was collected using a test bed set up as shown in Figure 2.
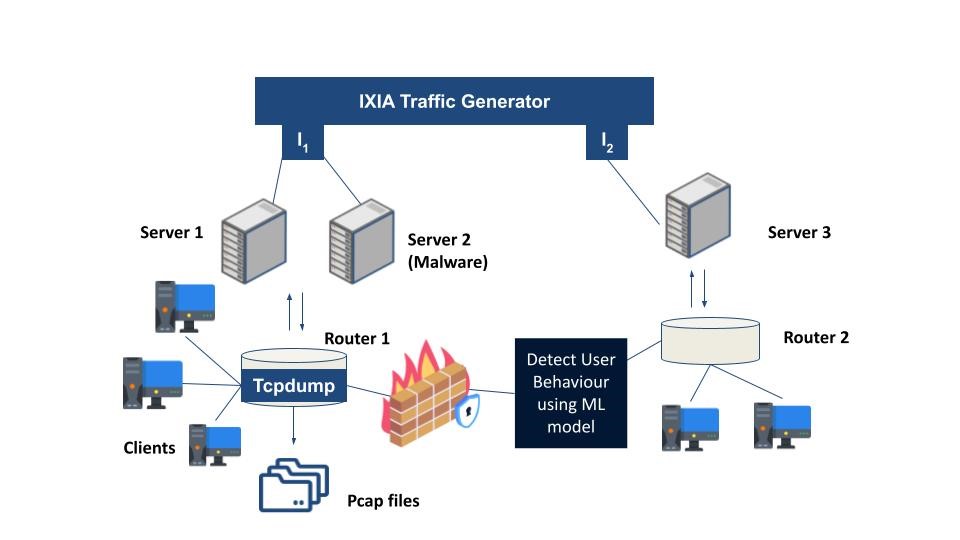
Figure 2
As shown in the figure IXIA traffic generator was used with 3 virtual servers which are connected to 2 virtual interfaces for intercommunication. Server 1 and 3 are generating normal traffic and server 2 is generating malware traffic and then traffic is distributed over the network up to clients via Router 1 and Router 2. These routers are connected to a firewall which is configured to pass all the traffic either normal or abnormal. The tcpdump tool is installed on router 1 to capture the Pcap files of the simulation uptime and Pcap files are further processed to extract datasets to excel sheets.
In the implementation we mainly used the libraries from python scikit-learn, Creme was used to train the models described in the methodology section to evaluate the final trustworthiness of the clients.
Results and Analysis
For the machine learning training process, we used different subsets of datasets of the original dataset for 9 types of attacks. For each attack-wise dataset, we used the information gain technique to identify the most important N features for that particular dataset. For DoS attacks, we obtained the information gain results as in Figure 3. Features with the highest gain(Left side of the figure) are the most important features. For the machine learning training process, we used different subsets of datasets of the original dataset for 9 types of attacks. For each attack-wise dataset, we used the information gain technique to identify the most important N features for that particular dataset. For DoS attacks, we obtained the information gain results as in Figure 3. Features with the highest gain(Left side of the figure) are the most important features.
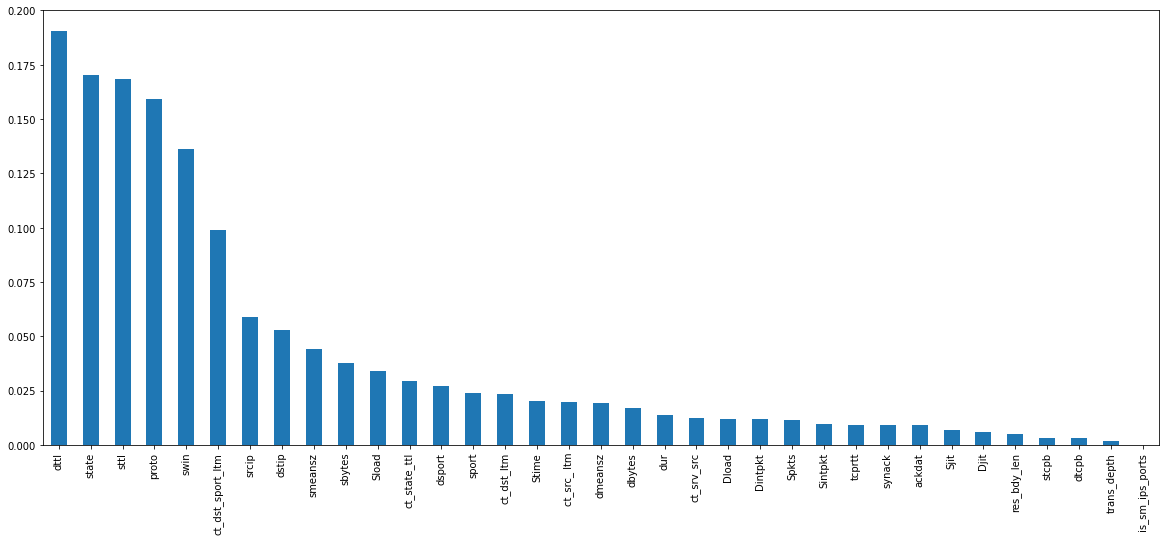
Figure 3
For choosing a suitable N value, the dataset was trained using the Random Forest algorithm for different no of features.
| No of features | Accuracy |
|---|---|
| 5 | 90.57% |
| 10 | 95.83% |
| 15 | 98.74% |
As the N of features (N), 15 was chosen since it gives high accuracy score among tested values.
Each attack-wise dataset was trained with different kinds of Machine learning Algorithms and the most suitable machine-learning algorithm was chosen by comparing the F1 score for the test set. The below table shows the best machine algorithm chosen for each attack-wise dataset.
| Attack Type | Algorithm | F1 Score | Accuracy |
|---|---|---|---|
| Dos | ANN | 0.86 | 99.82 % |
| Analysis | Random Forrest | 0.69 | 99.44 % |
| Backdoors | ANN | 0.57 | 99.85 % |
| Fuzzers | Random Forrest | 0.63 | 98.17 % |
| Exploits | KNN | 0.79 | 98.98 % |
| Generic | KNN | 0.98 | 99.76 % |
| Reconnaissance | KNN | 0.67 | 99.41 % |
| Shellcode | ANN | 0.42 | 99.09 % |
| Worms | KNN | 0.45 | 98.47 % |
After applying ensemble learning, online learning was performed to simulate the continuous learning behaviour. This was also done using different machine learning algorithms and Accuracy score and F1 Score values are compared as in Figure 4 and Figure 5.
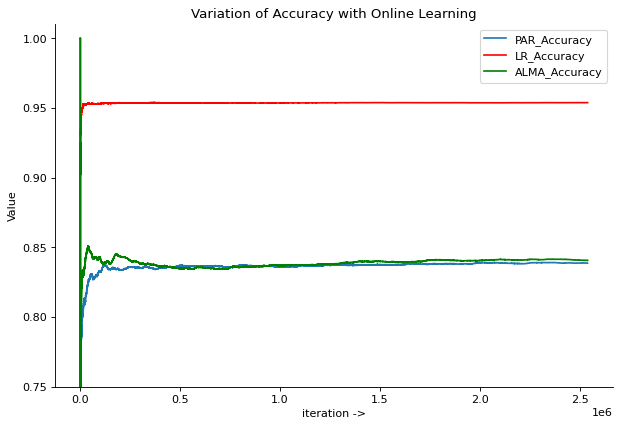
Figure 4
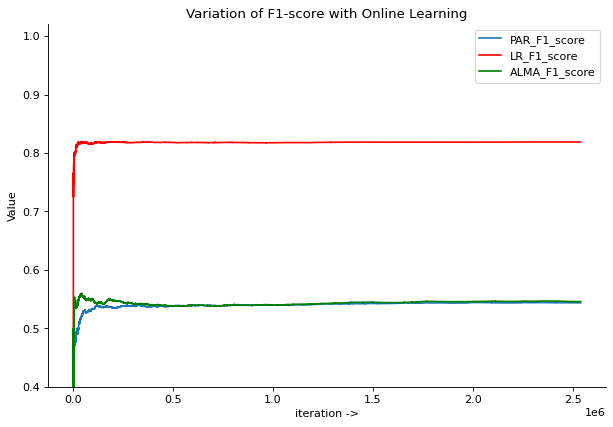
Figure 5
Logistic Regression gave the best accuracy score and F1 score among tested algorithms.
Conclusion
The zero trust model is a cutting-edge strategy for network security that requires verification of every user and device whenever they want to access resources on a secure network.This is still true whether the object or person is inside or outside the network boundary.This fixes a lot of problems with the traditional network security model, which was based on the idea of a security perimeter. In this research, we developed a machine learning-based Zero Trust architecture. Based on the findings, we presented evidence of how classification machine-learning techniques may aid in enhancing the application of Zero Trust principles throughout a complicated environment. Additionally, it demonstrates how admins’ manual effort might be used through machine learning to improve the machine learning model for better judgment in the future while still allowing traffic. Here, in each step we tried, several machine learning algorithms and then based on performance metrics we chose the best algorithm. In our case, classification machine learning algorithms showed more accurate results rather than anomaly detection algorithms. Furthermore, this research used a reliable UNSW-NB-15 dataset with 9 types of different attacks and these attack types were used to create individual trust metrics. By combining individual trust metric values, the final trust value was calculated. Moreover, this research shows how incremental machine learning (Online learning) can be used to simulate the continuous verification principle of Zero Trust.