
A Spatiotemporal Approach to Tri-Perspective Representation for 3D Semantic Occupancy Prediction
Sathira Silva*, Savindu Wannigama*, Gihan Jayatilaka $\ddagger$, Muhammad Haris Khan $\ddagger$, Prof. Roshan Ragel $\dagger$
* Equal contribution, $\ddagger$ Project Co-supervisor, $\dagger$ Project Supervisor
Paper | Poster
Abstract
Holistic understanding and reasoning in 3D scenes are crucial for the success of autonomous driving systems. The evolution of 3D semantic occupancy prediction as a pretraining task for autonomous driving and robotic applications captures finer 3D details compared to traditional 3D detection methods. Vision-based 3D semantic occupancy prediction is increasingly overlooked in favor of LiDAR-based approaches, which have shown superior performance in recent years. However, we present compelling evidence that there is still potential for enhancing vision-based methods. Existing approaches predominantly focus on spatial cues such as tri-perspective view (TPV) embeddings, often overlooking temporal cues. This study introduces S2TPVFormer, a spatiotemporal transformer architecture designed to predict temporally coherent 3D semantic occupancy. By introducing temporal cues through a novel Temporal Cross-View Hybrid Attention mechanism (TCVHA), we generate Spatiotemporal TPV (S2TPV) embeddings that enhance the prior process. Experimental evaluations on the nuScenes dataset demonstrate a significant +4.1$% of absolute gain in mean Intersection over Union (mIoU) for 3D semantic occupancy compared to baseline TPVFormer, validating the effectiveness of S2TPVFormer in advancing 3D scene perception.
Introduction
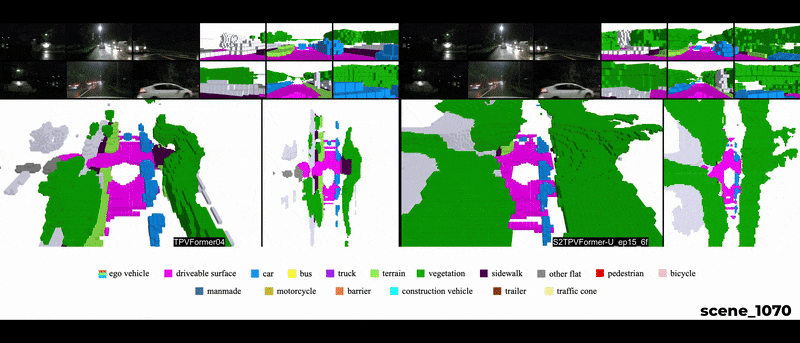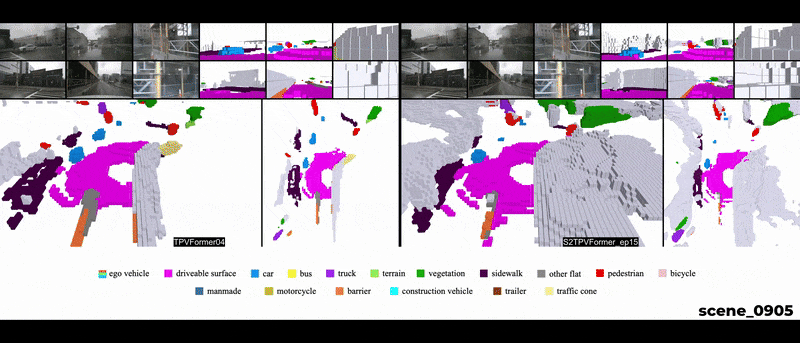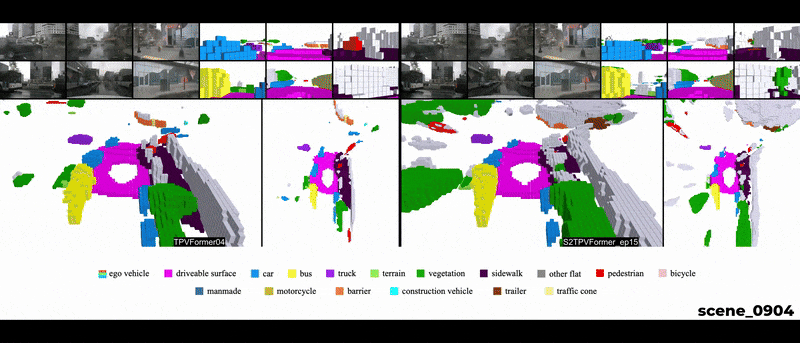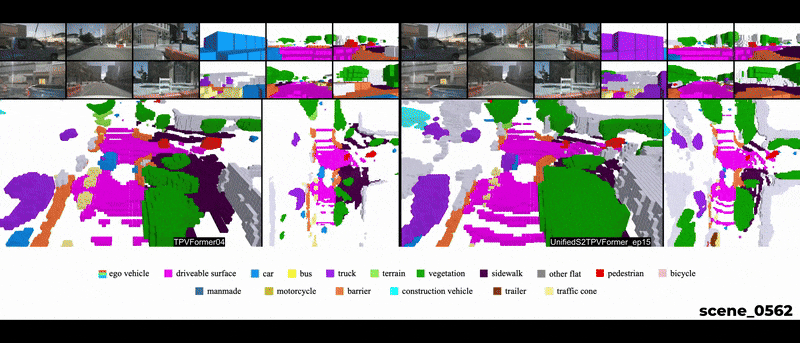
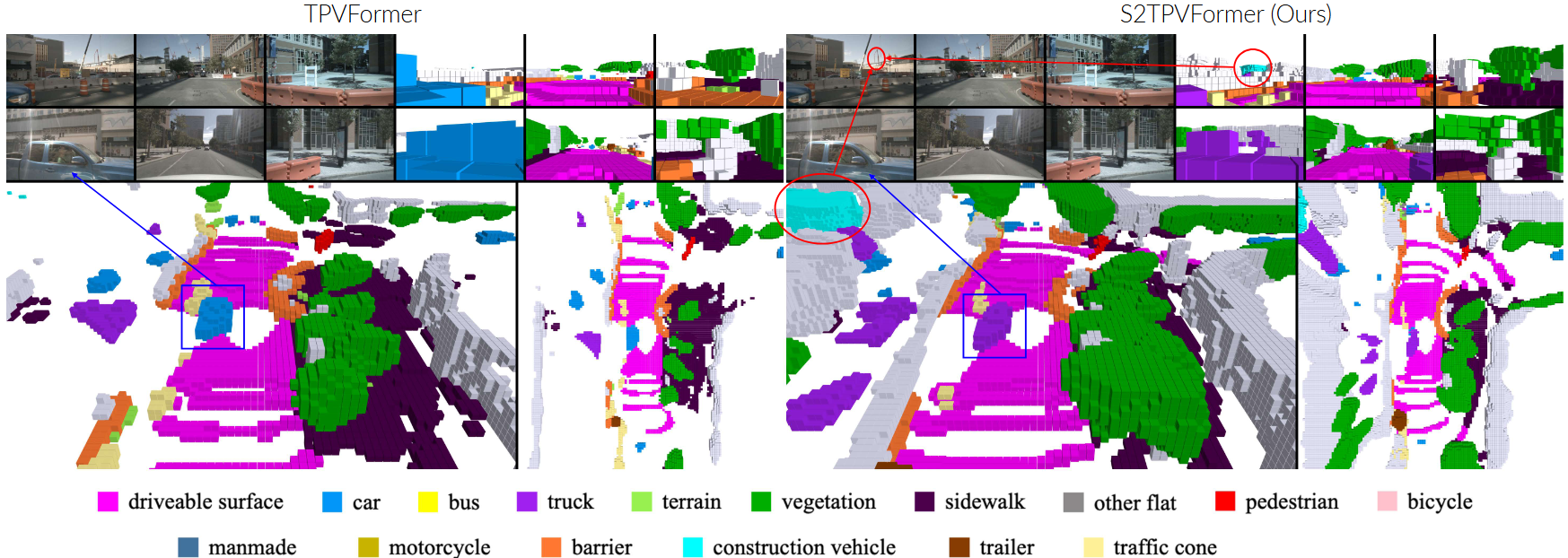
Temporal reasoning holds equal importance to spatial reasoning in a cognitive perception system. In human perception, temporal information is crucial for identifying occluded objects and determining the motion state of entities. A system proficient in spatiotemporal reasoning excels in making inferences with high temporal coherence. While previous works emphasize the significance of temporal fusion in 3D object detection, earlier attempts at 3D Semantic Occupancy Prediction (3D SOP) often overlooked the value of incorporating temporal information. The current state-of-the-art in 3D SOP literature seldom exploits temporal cues. This is evident in TPVFormer’s SOP visualizations, where adjacent prediction frames lack temporal coherence as they rely solely on the current time step for semantic predictions.
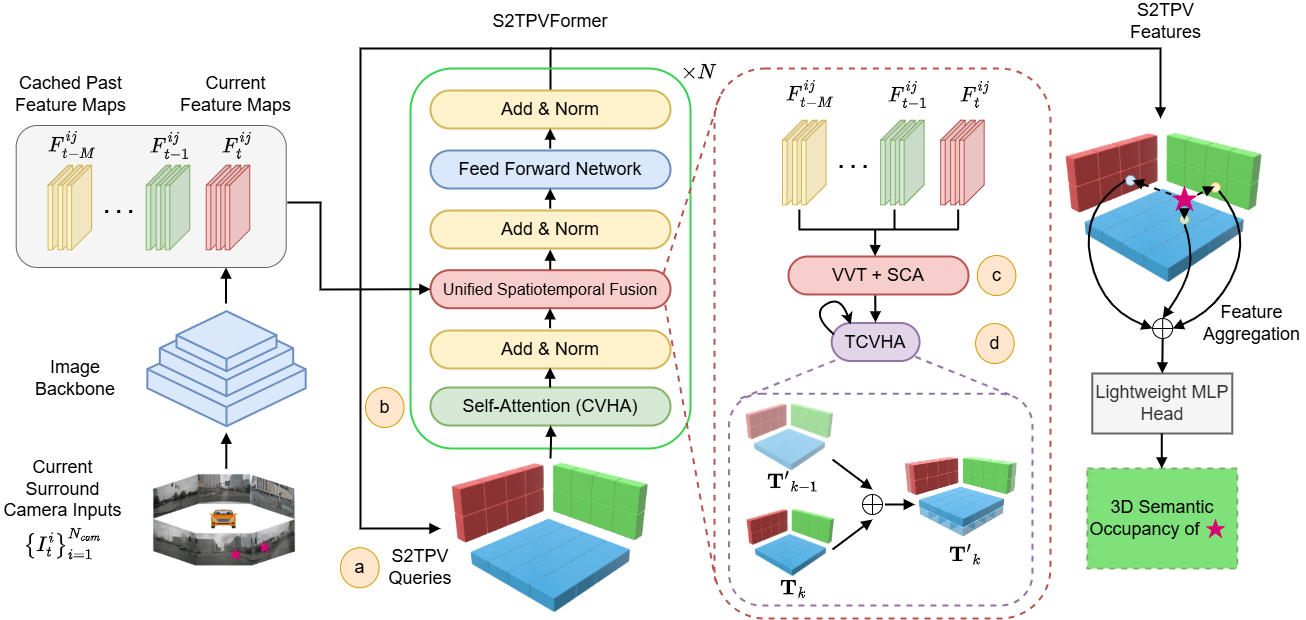
This work introduces S2TPVFormer, a variant of TPVFormer, which utilizes a spatiotemporal transformer architecture inspired by BEVFormer, for dense and temporally coherent 3D semantic occupancy prediction. Leveraging TPV (Top View and Voxel) representation, the model’s spatiotemporal encoder generates temporally rich embeddings, fostering coherent predictions. The study proposes a novel Temporal Cross-View Hybrid Attention mechanism, enabling the exchange of spatiotemporal information across different views. To illustrate the efficacy of temporal information incorporation and the potential of the new attention mechanism, the research explores three distinct temporal fusion paradigms.
Overview of our Contributions
To summarize, this work contributes in the following ways;
- We introduce S2TPVFormer, featuring a novel temporal fusion workflow for TPV representation, and demonstrate how CVHA facilitates the sharing of spatiotemporal information across the three planes.
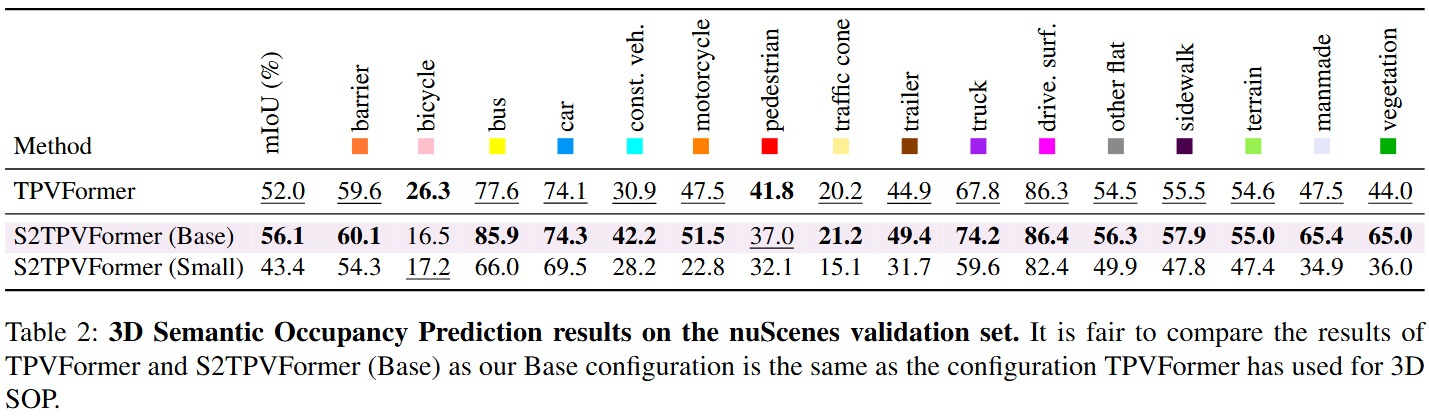
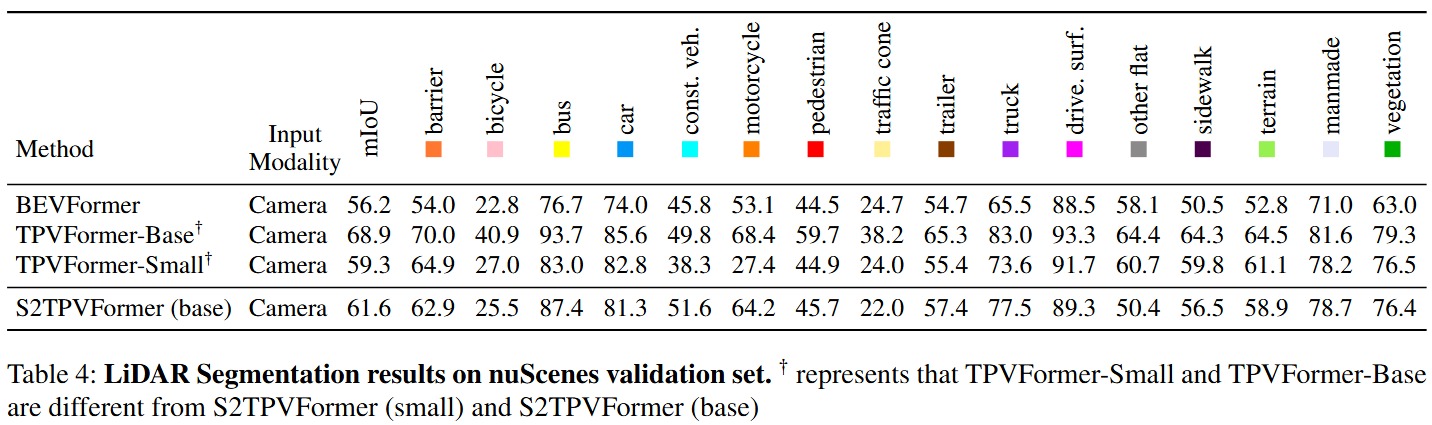
- S2TPVFormer achieves significant improvements in the 3D SOP task on the nuScenes validation set, with a +4.1% mIOU gain over the baseline TPVFormer, highlighting that vision-based 3D SOP still has considerable potential for improvement.
Architecture
Model Configurations
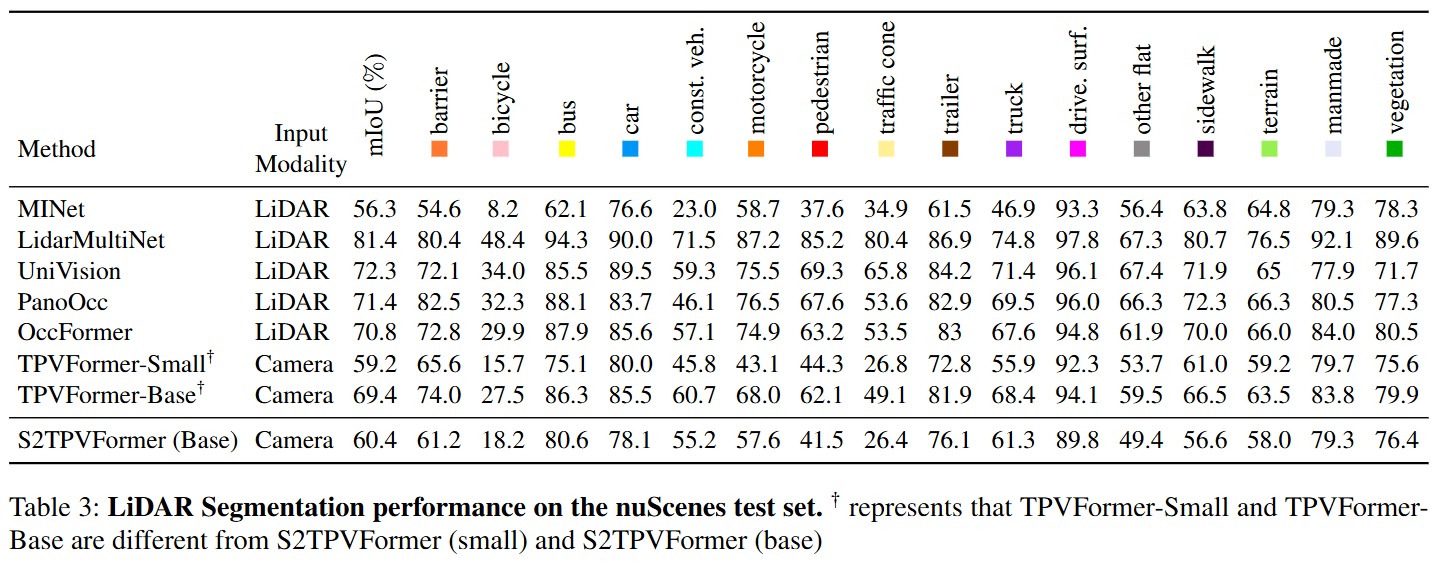
Quantitative Results
Qualitative Results
Team
-
E/17/331 - SILVA H.S.C. - e17331@eng.pdn.ac.lk
-
E/17/369 - WANNIGAMA S.B. - e17369@eng.pdn.ac.lk
Supervisors
-
Gihan Jayatilaka - firstname_AT_umd_DOT_edu
-
Muhammad Haris Khan - muhammad.haris@mbzuai.ac.ae
-
Prof. Roshan Ragel - roshanr@eng.pdn.ac.lk