Click the thumbnail above to watch the video lecture on YouTube
19.1 Introduction
Multiprocessor systems represent a fundamental paradigm shift in computer architecture, using multiple processors on the same chip to execute multiple programs or threads simultaneously when traditional performance improvement techniques—clock frequency scaling and instruction-level parallelism—reached physical and practical limits. This lecture explores the evolution toward multiprocessor architectures driven by power walls and parallelism walls, examines the critical challenge of cache coherence that arises when multiple processors maintain private caches of shared memory, and analyzes solutions including bus snooping protocols like MESI and scalable directory-based coherence schemes. We compare architectural organizations from uniform memory access (UMA) to non-uniform memory access (NUMA), understanding how different designs balance simplicity, performance, and scalability for systems ranging from dual-core smartphones to thousand-processor supercomputers.
19.2 Introduction to Multiprocessors
Multiprocessor systems address performance limitations encountered with single processor systems by employing multiple processors on the same chip to execute multiple programs or threads simultaneously.
19.3 Performance Evolution Background
19.3.1 Historical Performance Improvements
Early Methods: Clock Frequency Scaling
Approach:- Increasing clock frequency (reducing clock cycle time)
- Goal: Spend less time per instruction
- Hit barrier at ~4 GHz: Power wall problem
- Excessive power dissipation caused overheating
- Cooling became inadequate
- Could not sustainably increase frequency further
Instruction Level Parallelism (ILP)
Techniques:- Pipelining: Process multiple instructions simultaneously
- Utilize different hardware components at same time
- Example: Execute one instruction while fetching another
- Advanced techniques: Multiple issue, out-of-order execution
- Exploit parallelism inherent in programs
- Programs contain limited inherent parallelism
- Dependencies prevent unlimited parallel execution
- Hit "parallelism wall"
- Can't exploit more parallelism beyond program's inherent limits
19.3.2 Moore's Law Context
Observation:- Number of transistors doubles every 2 years
- Technology improves, more transistors available
19.4 Multiprocessor Approach
19.4.1 Key Characteristics
- Multiple processor cores on same chip
- Execute multiple instruction streams simultaneously
- Run multiple programs/threads in real time (true parallelism)
- Different from single processor illusion of parallelism
19.4.2 Terminology
- Processing Elements (PE): Common term for individual processors
- Each PE is a complete CPU with fetch, decode, execute units
19.4.3 Key Problem: Communication Between Processors
- Multiple processors executing simultaneously
- Programs often need to communicate/share data
- Splitting programs into threads requires coordination
- Communication is central design challenge
19.5 Shared Memory Multiprocessors (SMM)
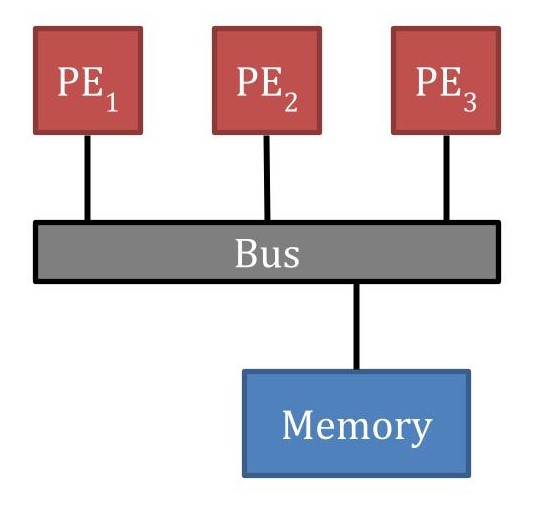
19.5.1 Most Common Approach
Architecture:- Communication through shared memory
- All processors access same physical address space
- Memory device connected via common bus/interconnect
19.5.2 Operating System Role
Responsibilities:- OS code stored in shared memory
- OS shared between all processors
- Manages memory access arbitration
- Performs workload balancing
- Ensures processors access only authorized memory portions
19.5.3 Workload Balancing
Purpose:- OS distributes tasks among processors
- Goal: All processors working in parallel
- Avoid idle processors
- Maximize overall system utilization
19.6 Memory Contention Problem
19.6.1 Inherent Issue
Challenge:- Multiple processors accessing same memory device
- Competition for memory access
- Processors must wait for memory availability
- Synchronization overhead
- Access time increases with contention
19.6.2 Effect on Performance
Bottleneck:- Memory becomes bottleneck
- Bus connects all processors to memory
- If one processor using memory, others must wait
- Can take hundreds of cycles
- Limits scalability
19.7 Uniform Memory Access (UMA)
19.7.1 Definition
Characteristics:- Each processor sees memory in exact same way
- Same average memory access time for all processors
- Access time independent of which processor is accessing
- By design, no difference in access time (ignoring contention)
19.7.2 Also Known As
- Symmetric Multiprocessors (SMP)
- Both terms used interchangeably
19.7.3 Key Properties
- Shared address space
- Uniform view of memory by all processors
- All processors experience same average latency
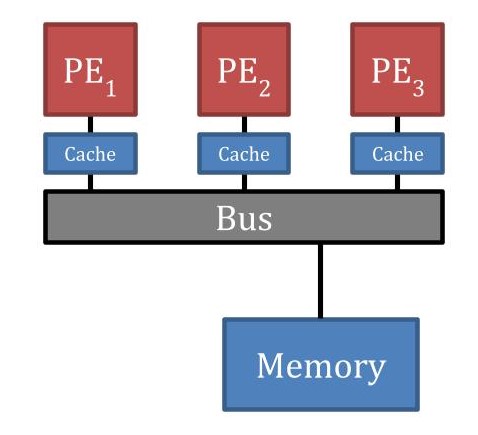
19.8 Solution to Contention: Caches
19.8.1 Using Local Caches
Approach:- Each processor has private cache
- Based on locality principles (temporal and spatial)
- Most memory accesses served at cache level
- Only small percentage (misses) go to main memory
- Reduces bus/memory contention significantly
19.8.2 Benefits
- Exploits locality in programs
- Minimizes memory accesses
- Reduces bottleneck effect
- Allows better scalability
19.8.3 New Problem: Cache Coherence
- Shared data blocks can be in multiple caches
- Updates in one cache not automatically reflected in others
- Need mechanism to maintain consistency
19.9 Cache Coherence Problem
19.9.1 The Issue
Scenario:- Multiple caches have copies of same data block
- One processor writes to that block
- Other caches have stale (old) data
- Processors see different values for same address
- Data becomes incoherent
19.9.2 Example Sequence
- PE1 reads X (value = 1) → Cached in PE1
- PE2 reads X (value = 1) → Cached in PE2
- PE1 writes X = 0 → PE1 cache updated
- Memory may or may not be updated (depends on write policy)
- PE2 still sees X = 1 (stale data)
- Inconsistency: Same address, different values
19.9.3 With Write-Through Policy
- PE1 writes X = 0 → Cache and memory updated
- Memory has correct value
- But PE2 cache still has old value (X = 1)
- Coherence still lost
19.9.4 With Write-Back Policy
- PE1 writes X = 0 → Only cache updated
- Memory still has old value (X = 1)
- PE2 cache still has old value (X = 1)
- Both memory and PE2 incoherent with PE1
19.9.5 Requirement
- Cache coherence MUST be maintained
- Otherwise parallel programs execute incorrectly
- Get wrong results
- Latest updates must be visible to all processors
19.10 Bus Snooping
Common technique for cache coherence in SMP systems.
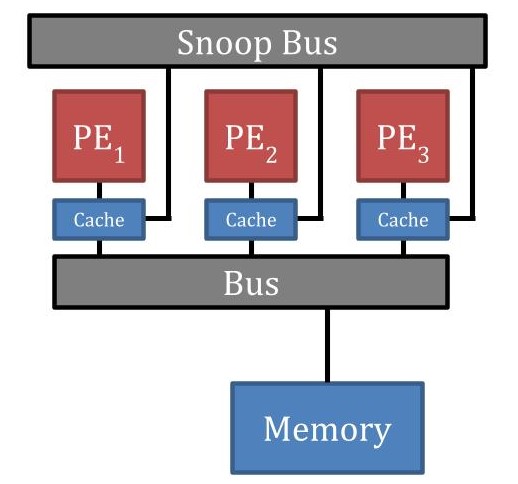
19.10.1 What is Bus Snooping?
Mechanism:- Dedicated bus for coherency control: Snoop bus
- Sole purpose: Control coherency of cache data
- Separate from memory bus
- Cache controllers communicate through snoop bus
19.10.2 How It Works
- Cache controller performs write to address
- Broadcasts address information on snoop bus
- All cache controllers listen to snoop bus
- Controllers check if they have same address cached
- If yes, take action based on protocol
19.10.3 Key Feature
- All caches monitor (snoop on) the bus
- Detect writes by other processors
- Take appropriate action to maintain coherence
19.11 Write Invalidate Protocol
19.11.1 Approach
- When write detected, invalidate own copy
- Group of protocols using this approach
- Most common and easiest to implement
19.11.2 Mechanism
On Write by Processor
- Update own cache
- Broadcast write address on snoop bus
On Receiving Write Broadcast
- Check if same address in own cache
- If yes: Mark block as INVALID (clear valid bit)
- Next access will be miss
19.11.3 With Write-Through Policy
- Memory always has up-to-date value
- On miss after invalidation: Fetch from memory
- Straightforward implementation
19.11.4 With Write-Back Policy
Challenge:- Only writing cache has up-to-date value
- Memory has stale value
- On miss after invalidation: Cannot fetch from memory
- Cache with invalid block places snoop read request on bus
- Cache controllers listen to snoop read
- Controller with valid up-to-date copy responds
- Supplies data through snoop bus
- More efficient than going to memory
- Avoids slow memory access
19.11.5 Complexity
Trade-offs:- More complex cache controller
- Snoop bus needs to carry data and addresses
- More hardware required
- Higher power consumption
- But better performance (less memory traffic)
19.12 Write Update Protocol
19.12.1 Alternative Approach
Concept:- Update own copy instead of invalidating
- Also called Write Broadcast
- Different action when write detected
19.12.2 Mechanism
On Write by Processor
- Update own cache
- Broadcast BOTH address AND data on snoop bus
On Receiving Write Broadcast
- Check if same address in own cache
- If yes: Update own copy with new data
- Keep block VALID
19.12.3 Benefits
- No miss on next access to same address
- Data already updated in all caches
- Don't need extra read operation
- Simpler cache controller (no snoop read needed)
19.12.4 Costs
- Snoop bus must carry data (wider bus)
- More hardware on snoop bus
- Higher power consumption
- More bus traffic
19.12.5 Comparison
- Simpler than write invalidate with write-back
- Fewer cache misses
- Higher bus bandwidth requirement
19.13 Real Protocol Implementations
19.13.1 Historical Protocols
Write Once Protocol
- Type: Write invalidate
- Write policy: Write-through on first write, write-back after
- One of first bus snooping protocols
Synapse N+1 Protocol
- Type: Write invalidate
- Write policy: Write-back
- Early implementation
Berkeley Protocol
- Type: Write invalidate
- Write policy: Write-back
- Used in Berkeley SPUR processor
Illinois Protocol (MESI)
- Type: Write invalidate
- Write policy: Write-back
- Used in SGI Power and Challenge systems
- Very popular, widely adopted
Firefly Protocol
- Type: Write update
- Write policy: Mixed (write-back for private data, write-through for shared data)
- Used in DEC Firefly and Sun SPARC systems
19.13.2 Most Common Combination
- Write invalidate protocols
- Write-back policy
- Reduces memory accesses (expensive in terms of time)
- Easier to implement than write update
- Good balance of performance and complexity
19.14 MESI Protocol Details
Named after four states: Modified, Exclusive, Shared, Invalid
Most popular cache coherency protocol, used in Intel Pentium and IBM PowerPC processors.
19.14.1 Four Block States (Requires 2 Bits)
1. INVALID (I)
- Data not valid
- Block cannot be used
- Must fetch from elsewhere
2. SHARED (S)
- Multiple caches have copies of this block
- All copies have same value
- Value consistent with memory
- Memory has up-to-date value
3. EXCLUSIVE (E)
- Only cached copy in entire system
- No other cache has this block
- Value consistent with memory
- Memory has up-to-date value
4. MODIFIED (M)
- Only cached copy in system
- Value INCONSISTENT with memory
- This cache has most recent value
- Memory has stale value
- Block is "dirty"
19.15 MESI Protocol State Transitions
19.15.1 Example with PE1, PE2, PE3
Initial State: Variable X = 1 in memory, all cache entries invalidStep 1: PE1 Reads X
Actions:- Check other caches (snoop read request)
- No other cache has X
- Fetch from memory
- State transition: Invalid → Exclusive
- PE1: X = 1 (Exclusive)
Step 2: PE3 Reads X
Actions:- Check other caches (snoop read request)
- PE1 responds (has Exclusive copy)
- PE1 supplies data to PE3
- PE1: Exclusive → Shared
- PE3: Invalid → Shared
- Both PE1 and PE3: X = 1 (Shared)
- Consistent with memory
Step 3: PE3 Writes X = 0
Actions:- Block in PE3 was Shared
- Update local cache
- Broadcast invalidate on snoop bus
- State transition: Shared → Modified
- PE3: X = 0 (Modified)
- PE1 receives invalidate:
- State transition: Shared → Invalid
- PE1: X = ? (Invalid)
- Memory still has X = 1 (stale)
Step 4: PE1 Reads X
Actions:- Block in PE1 is Invalid (tag matches but invalid)
- Place snoop read request on bus
- PE3 has Modified copy (most up-to-date)
- PE3 responds to snoop read:
- Supplies data to PE1 through snoop bus
- Writes back to memory
- State transition: Modified → Shared
- PE1 receives data:
- State transition: Invalid → Shared
- PE1: X = 0 (Shared)
- PE3: X = 0 (Shared)
- Memory: X = 0 (updated)
- All consistent
19.15.2 Key Points
- Coherency maintained throughout
- Invalidations prevent stale data reads
- Modified state identifies most recent value
- Snoop reads fetch from other caches efficiently
- Write-backs occur when transitioning from Modified to Shared
19.16 Scalability of UMA Systems
19.16.1 Limitation
Challenges:- Bus snooping doesn't scale well
- Bus contention increases with more processors
- Snoop bus becomes bottleneck
- Memory bus also becomes bottleneck
19.16.2 Practical Limit
- Up to ~32 processing elements with bus-based design
- Not a hard threshold but approximate practical limit
- Beyond this, contention significantly degrades performance
19.16.3 Alternative Interconnects
Crossbar Switches
- Alternative to bus-based architecture
- Allows multiple simultaneous connections
- Better than simple bus
Multi-Stage Crossbar Switch Network
- Multiple crossbar switches in network topology
- Increased parallelism in interconnect
- Can connect multiple memory banks simultaneously
- Increases scalability
19.16.4 Improved Scalability
- With crossbar networks: Up to ~256 processing elements
- Still limited but much better than bus-based
- Trade-off: More complex hardware
19.17 Non-Uniform Memory Access (NUMA)
19.17.1 Designed for Even Higher Scalability
Goals:- Target: Thousands of processing elements
- Beyond limits of UMA systems
- Still uses shared memory model
- Communication through shared address space
19.17.2 Key Difference from UMA
Non-Uniform Access Times:- Memory access time DEPENDS on which processor is accessing
- Different processors experience different latencies
- Memory perspective is non-uniform
19.17.3 Architecture
Structure:- Each processor has local memory
- Faster to access local memory
- Slower to access remote memory (other processors' local memory)
- But all memory accessible by all processors (shared address space)
19.17.4 Access Time Difference
- Remote memory access: 4-5 times more cycles than local
- Significant performance impact
- Programming must consider locality
19.17.5 Operating System Role
Optimization Responsibilities:- Must use special algorithms for memory optimization
- Workload distribution affects performance
- Should relocate memory blocks for optimization
- Goal: Maximize local accesses, minimize remote accesses
- Global optimization problem
19.18 Two Types of NUMA
19.18.1 NC-NUMA (Non-Cached NUMA)
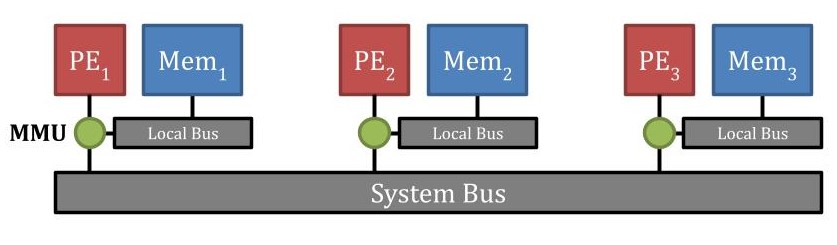 Characteristics:
Characteristics:
- No caches shown in architecture
- Processors directly access memory
- Simpler but slower
19.18.2 CC-NUMA (Cache-Coherent NUMA)
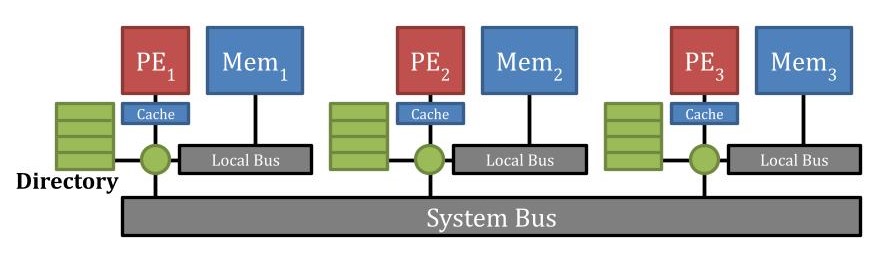 Characteristics:
Characteristics:
- Includes caches at each node
- Must maintain cache coherence
- More complex but better performance
- Cannot use bus snooping (not scalable enough)
- Solution: Directory-based coherence
19.19 Directory-Based Cache Coherence
Used in CC-NUMA systems for scalable cache coherence.
19.19.1 What is Directory?
Definition:- Data structure tracking cache contents
- Distributed across system
- Stores information about which blocks are cached where
- Can be in memory or separate hardware
19.19.2 Purpose
Functionality:- Cache controllers check directory to find block locations
- Determines if other caches have copies of block
- Enables coherence without bus snooping
- Scalable to thousands of processors
19.19.3 Organization
Distributed Structure:- Directory can be distributed
- Each node has local directory
- Local directory tracks blocks from local memory address range
- Information about which caches have those blocks
- Blocks from other address ranges tracked in other directories
19.19.4 Operation
Access Process:- Cache controller accesses appropriate directory
- Local directory if accessing local address range
- Remote directory if accessing remote address range
- Directory provides information about block locations
- Can then send invalidations or updates as needed
19.19.5 Write Policy
- Typically use write-through policy
Key Takeaways
- Multiprocessors overcome single-processor performance limitations
- Shared memory provides communication mechanism between processors
- Cache coherence is essential for correct parallel program execution
- Bus snooping works well for small-scale systems (up to ~32 processors)
- MESI protocol is widely adopted for cache coherence
- UMA systems provide uniform access but limited scalability
- NUMA systems enable thousands of processors with non-uniform access
- Directory-based coherence enables scalable cache coherence
- Operating system plays crucial role in workload balancing and optimization
- Trade-offs exist between simplicity, performance, and scalability
Summary
Multiprocessor systems have become the standard in modern computing, from smartphones to supercomputers, enabling the parallel processing power required for contemporary applications while managing the complex interactions between multiple processors sharing memory resources.